DriftWorld — World Model Framework for Robot Manipulation
Overview
DriftWorld is a world model framework that predicts the next visual state of a robot manipulation scene given the current image and action. It implements four generative architectures — VAE, DDPM, Flow Matching, and Drifting Models — on a shared DiT backbone, enabling fair comparison under identical conditions. The goal is to find efficient world models suitable for real-time model-based planning in robotics.
Architecture
All four models share the same pipeline and backbone, differing only in the generative mechanism:
Image (256×256) → [Frozen SD-VAE Encoder] → z (4×32×32)
│
┌─────────────────┴─────────────────┐
│ World Model f(z_t, a_t, r_t) │
│ │
│ Shared DiT-S/2 backbone (~33M) │
│ + AdaLN-Zero conditioning │
│ │
│ Variants: │
│ • VAE (1-step, blurry) │
│ • DDPM (50-step DDIM) │
│ • Flow Match (5-step Euler) │
│ • Drifting (1-step, WIP) │
└─────────────────┬─────────────────┘
│
ẑ_{t+1} + r̂_{t+1}
│
[Frozen SD-VAE Decoder] → Image (256×256)
Inputs: current image latent z_t, 7D relative action a_t, 15D proprioception r_t
Outputs: predicted next image latent ẑ_{t+1}, predicted next proprioception r̂_{t+1}
Results
Autoregressive Rollout Comparison
Given the first frame and a sequence of 64 expert actions (push_blue_block_left), each world model autoregressively predicts the next 64 frames.
| Training set — Columns: GT | CALVIN Sim | VAE | Flow(5) | DDPM(50) |

| Validation set (unseen data) — Columns: GT | VAE | Flow(5) | DDPM(50) | DDPM(100) |

DDPM collapses to noise on unseen data. Only VAE and Flow Matching survive 64-step autoregressive rollout.
Key Findings
| Model | Training Rollout | Validation Rollout | Overall |
|---|---|---|---|
| VAE | Stable, blurry | Stable, blurry | Best stability, worst sharpness |
| Flow(5) | Stable, sharp | Stable, sharp | Best overall |
| DDPM(50) | Stable | Collapsed to noise | Overfits, unsuitable for rollouts |
| Drifting | Mode collapsed | N/A | WIP |
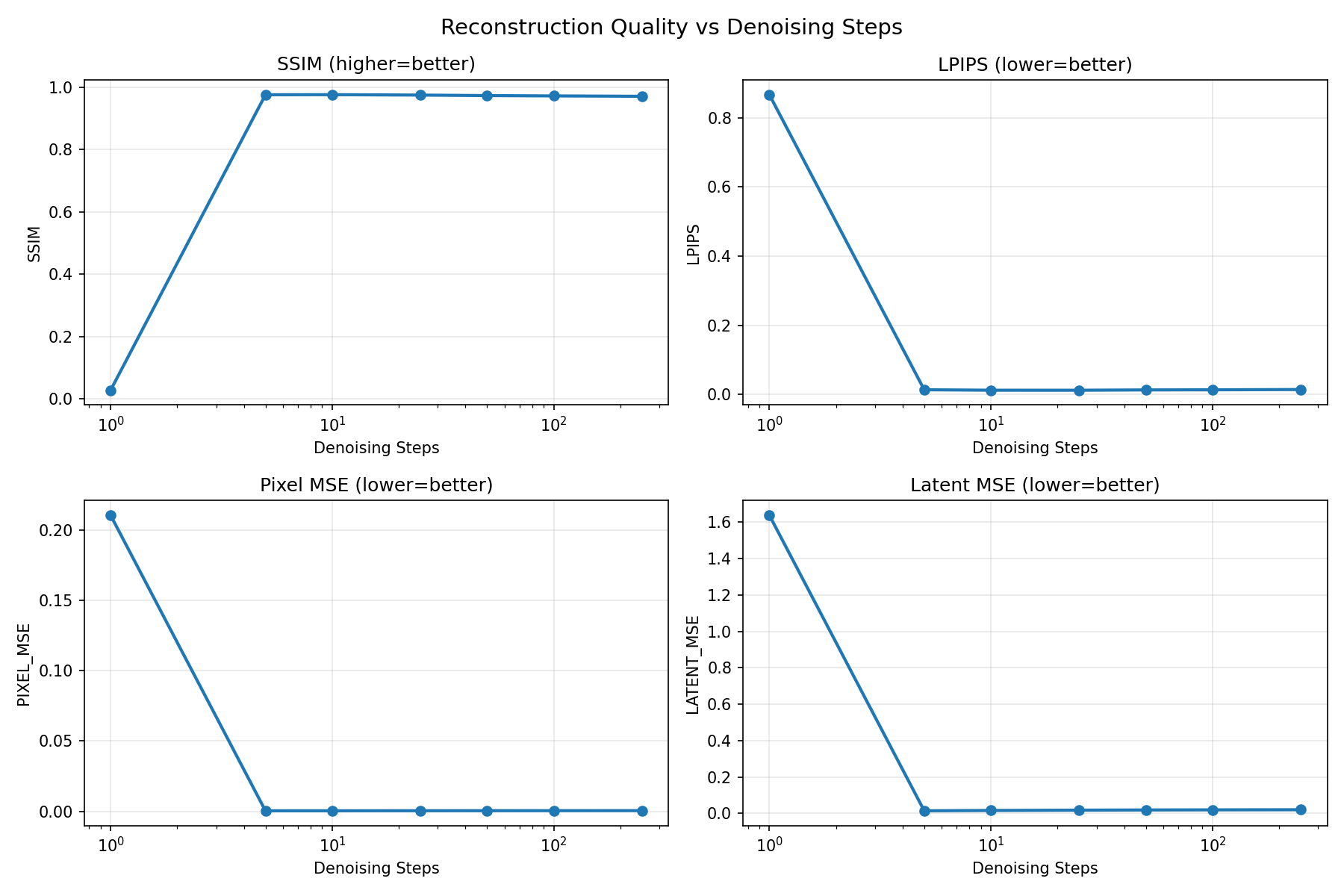
DDIM Denoising Step Sweep
Single-step reconstruction quality as a function of denoising steps. During this analysis, I discovered a critical clip_sample bug in the DDIM scheduler — SD-VAE latents range [-3.5, 3.2], not [-1, 1], so the default clipping was destroying latent values. After the fix, 5 DDIM steps achieves SSIM 0.976, nearly identical to 250 steps.
Flow Matching Step Sweep
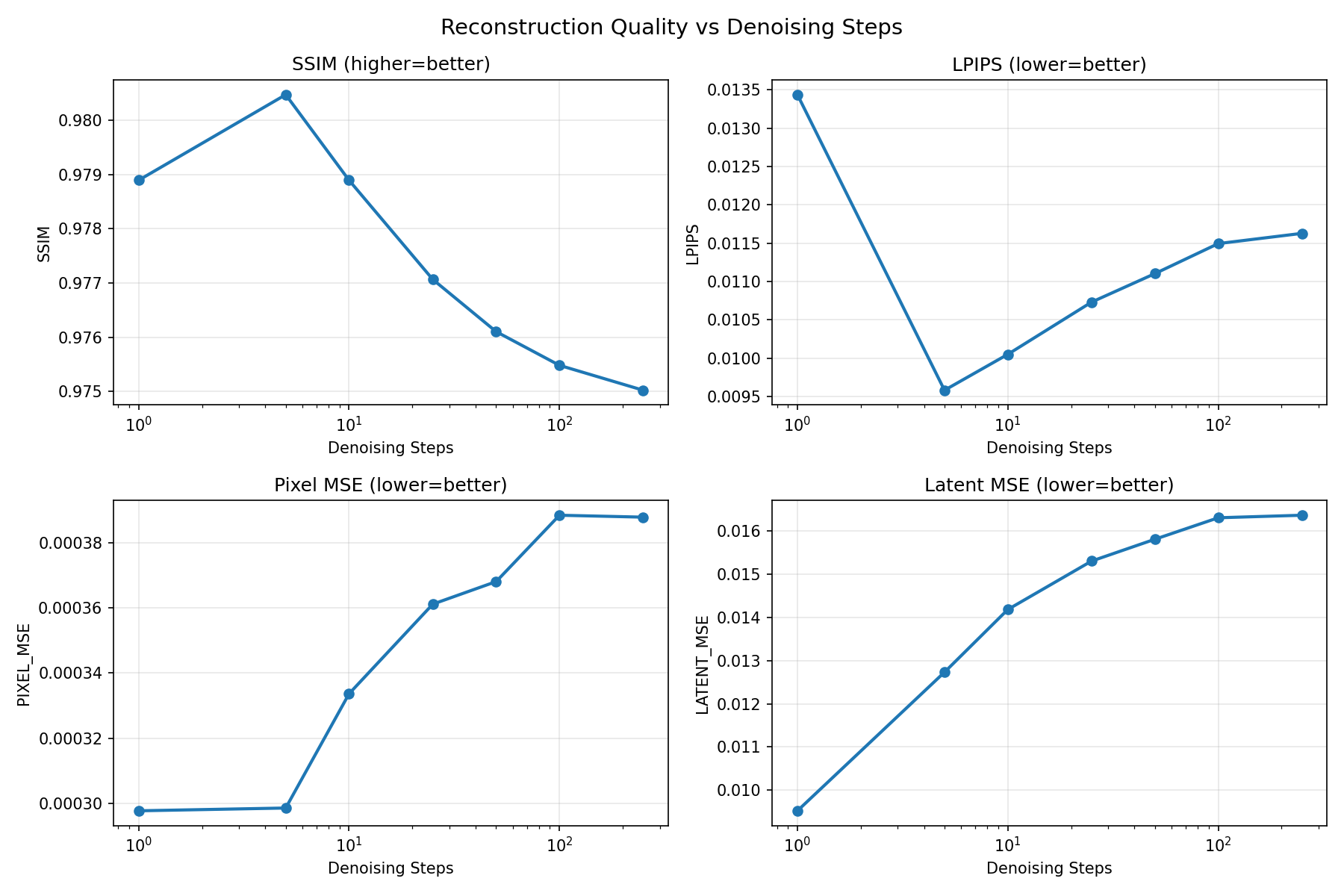
Autoregressive rollout quality as a function of Euler integration steps. Counterintuitively, more steps decreases rollout quality — each step introduces small errors that compound autoregressively. 5 Euler steps is optimal (avg SSIM 0.892 over 64-step rollout).
Technical Details
- Backbone: DiT-S/2 with AdaLN-Zero conditioning, ~33M parameters
- Dataset: CALVIN task_D_D (single-environment robot manipulation)
- Training: 200K steps per model, AdamW, OneCycleLR, FP16 mixed precision
- Latent space: Frozen Stable Diffusion VAE (256×256 → 4×32×32)
- Metrics: SSIM, LPIPS (AlexNet), Pixel MSE, Latent MSE
- Infrastructure: Hydra configs, W&B logging, uv for dependency management
Current Status
Flow Matching at 5 Euler steps is the clear winner for autoregressive rollouts, combining sharp predictions with stable multi-step propagation. The Drifting Model currently suffers from mode collapse and requires architectural changes (residual connections, batch-level drifting field). PPO policy training in the learned world model is underway, with preliminary infrastructure for training and evaluating policies in CALVIN simulation.